Memory Management: Arena Allocators
The Problem
When using languages where you must look after the memory management yourself we often use APIs like malloc()/new to allocate memory, which come with the problem of remembering to free()/delete the allocation. This manual approach can lead to memory leaks and complicated code bases.
C++ does a good job solving this problem using RAII, where we are tying memory allocation to object lifetimes. C++ also makes use of smart pointers to help with this, it makes memory allocated separately tied to an object lifetime. Even in cases where we have managed to remove the manual allocation and deallocation you can end up with heap fragmentation and allocations not in contiguous memory. For example nodes in a linked list end up far apart from each other. This can have an impact on performance due to poor cache locality for example.
Hopefully you can see where the problem comes from when using these general allocators, which definitely have their uses. Here is where custom allocators come in, and in this article I will be writing about an arena allocator/linear allocator/bump allocator.
Arena Allocators
An arena is actually rather simple. Upon creation you allocate a large block of memory. Now when allocating anything you allocate it within this large block of memory and push the offset (or bump the pointer). Take a look at the diagram below:
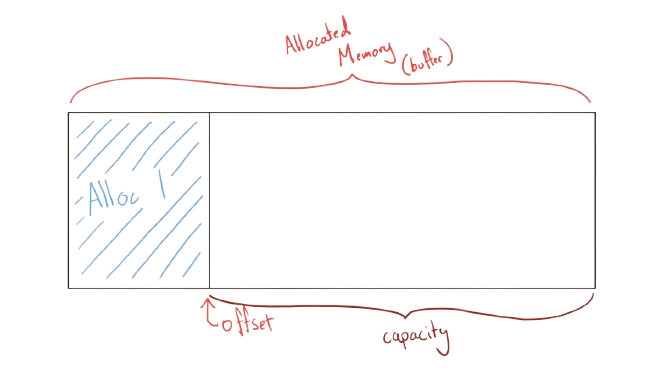
This is how an arena works. Get the offset, allocate the memory you need, bump the offset and repeat. Within here you will have checks to ensure that there is enough capacity and you do not exceed the size of the buffer. Once you are done using the arena, you can free the memory, or if you want to reuse the arena you can implement reset() which shifts offset back to the start of the arena. I will now walk through the implementation I used, please see references at the bottom for my inspiration.
Implementation
To start off I have a simple Arena, which has an allocate method, reset method. The memory allocation and deallocation is done within the constructor and destructor of the arena.
class Arena {
public:
explicit Arena(std::size_t size)
: capacity_(size), offset_(0) {
if (size == 0) throw std::invalid_argument("Arena size must be greater than 0");
buffer_ = static_cast<char*>(::operator new(size));
}
~Arena() {
if (buffer_) {
run_destructors();
::operator delete(buffer_);
}
}
// Copy and Move constructors are here
template <typename T>
[[nodiscard]] T* allocate(std::size_t count = 1) {
if (count > (std::numeric_limits<std::size_t>::max() / sizeof(T))) throw std::bad_alloc();
void* ptr = allocate_raw(sizeof(T) * count, alignof(T));
if (!ptr) throw std::bad_alloc();
return static_cast<T*>(ptr);
}
void reset() noexcept {
if (destructor_head_) run_destructors();
offset_ = 0;
}
private:
std::size_t capacity_;
std::size_t offset_;
char* buffer_ = nullptr;
void* allocate_raw(std::size_t size, std::size_t alignment) noexcept {
std::size_t aligned_offset = (offset_ + alignment - 1) & ~(alignment - 1);
if (aligned_offset < offset_) return nullptr;
if (aligned_offset > capacity_ || size > capacity_ - aligned_offset) return nullptr;
void* ptr = buffer_ + aligned_offset;
offset_ = aligned_offset + size;
return ptr;
}
};Everything is standard in here, I have bounds and overflow checking. There was also a conscious decision to calculate the aligned_offset manually and not use the standard function std::align. This would align the pointer for you, which you can use to update offset_. However, when I was benchmarking with std::align it was substantially slower. Hence my decision was to stick with calculating it manually. Another choice in my implementation was having two allocate functions, one essentially being a wrapper. allocate_raw currently does not have any exceptions in it, allowing it to be labled noexcept. This provides performance benefits, which comes not from the presence of the label itself, but the omission of std::bad_alloc in the if statements. However, on cases of allocations where we do fail, we should return the correct exception, hence the allocate method does have exceptions. This will also be required later when adding support for STL containers.
The next step within my implementation was allowing the construction and destruction of non-trivial types. This meant the addition of a couple new methods run_destructors() and create<T>(). In C++, it is worth noting that when creating an object using new like this double* d = new double(3.14). This does two things, it allocates the memory for the double, and then it creates the object. The create<T>() method aims to replicate this. It calls allocate followed by instantiating the object. If required, the destructor is non-trivial, it also creates a DestructorNode which I will use in my reversed linked list to run the destructors. Here is what they look like:
class Arena {
public:
// constructors, destructor, and other public methods
template <typename T, typename... Args>
[[nodiscard]] T* create(Args&&... args) {
std::size_t saved = offset_;
try {
T* ptr = allocate<T>();
DestructorNode* node = nullptr;
if constexpr (!std::is_trivially_destructible_v<T>) node = allocate<DestructorNode>();
::new(ptr) T(std::forward<Args>(args)...);
if constexpr (!std::is_trivially_destructible_v<T>) {
node->destructor = [](void* p) { static_cast<T*>(p)->~T(); };
node->object = ptr;
node->next = destructor_head_;
destructor_head_ = node;
}
return ptr;
} catch (...) {
offset_ = saved;
throw;
}
}
private:
struct DestructorNode {
void (*destructor)(void*);
void* object;
DestructorNode* next;
};
// other private member variables
DestructorNode* destructor_head_ = nullptr;
// other private member functions
void run_destructors() noexcept {
DestructorNode* node = destructor_head_;
while (node) {
node->destructor(node->object);
node = node->next;
}
destructor_head_ = nullptr;
}
};While watching the Handmade Hero game series Casey uses a "scratch arena" which is an arena where memory is persistent, but the contents of the arena are reset. I implemented this for my arena as well. It takes the form of a nested class within Arena and it requires some extra methods get added restored() and scratch(). The latter being used to actually initialize the scratch arena. When entering a new scope, you can initialize it by calling the scratch() method, and when the scope closes the scratch arena resets. Usually when using a scratch arena, the new scope will take two arenas: a permanent arena and a scratch arena (in this case a normal arena which is initialized as a scratch arena). The permanent arena is used for allocations which must remain when the scope closes, the latter for allocations which do not need to remain. Here is the implementation:
class Arena {
public:
class Scratch {
public:
explicit Scratch(Arena* arena) noexcept
: arena_(arena), checkpoint_offset_(arena->offset_), checkpoint_dtor_(arena->destructor_head_) {}
~Scratch() noexcept {
if (active_) arena_->restore(checkpoint_offset_, checkpoint_dtor_);
}
// Copy and Move constructors are here
template <typename T>
[[nodiscard]] T* allocate(std::size_t count = 1) {
return arena_->allocate<T>(count);
}
template <typename T, typename... Args>
[[nodiscard]] T* create(Args&&... args) {
return arena_->create<T>(std::forward<Args>(args)...);
}
void release() noexcept { active_ = false; }
private:
Arena* arena_;
std::size_t checkpoint_offset_;
void* checkpoint_dtor_;
bool active_ = true;
};
// constructors, destructor, and other public methods
[[nodiscard]] Arena::Scratch scratch() noexcept {
return Arena::Scratch(this);
}
private:
// private member variables and member functions
void restore(std::size_t offset, void* dtor_head) noexcept {
if (destructor_head_ != dtor_head) {
DestructorNode* node = destructor_head_;
DestructorNode* target = static_cast<DestructorNode*>(dtor_head);
while (node != target) {
node->destructor(node->object);
node = node->next;
}
destructor_head_ = target;
}
offset_ = offset;
}
};This makes up the most of the arena implementation, but this arena will not be able to allocate any STL containers. To support STL containers, we have to create a wrapper which I will call ArenaAllocator. The specification states what conditions a custom allocator must satisfy and I have attempted to implement them below:
template <typename T>
class ArenaAllocator {
public:
using value_type = T;
template <typename U>
struct rebind {
using other = ArenaAllocator<U>;
};
explicit ArenaAllocator(Arena* arena) noexcept : arena_(arena) {}
template <typename U>
ArenaAllocator(const ArenaAllocator<U>& other) noexcept : arena_(other.arena_) {}
template <typename U>
friend class ArenaAllocator;
T* allocate(std::size_t n) {
return arena_->allocate<T>(n);
}
void deallocate(T* /*p*/, std::size_t /*n*/) noexcept {}
bool operator==(const ArenaAllocator& other) const noexcept {
return arena_ == other.arena_;
}
bool operator!=(const ArenaAllocator& other) const noexcept {
return !(*this == other);
}
private:
Arena* arena_;
};That wraps up my implementation. You can see the full source code in this repository.
Benchmarks
Please see the repository for the full benchmarks file. This test uses a simple Google Benchmark setup. Here are the results:
----------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------
BM_NewDouble 8.99 ns 8.99 ns 80029268
BM_ArenaDouble 0.226 ns 0.226 ns 3098387068
BM_UnorderedMap_Insert/100 3500 ns 3500 ns 199325
BM_UnorderedMap_Insert/1000 34346 ns 34346 ns 20228
BM_UnorderedMap_Insert/10000 368759 ns 368753 ns 1967
BM_ArenaUnorderedMap_Insert/100 2355 ns 2354 ns 299770
BM_ArenaUnorderedMap_Insert/1000 21724 ns 21723 ns 32456
BM_ArenaUnorderedMap_Insert/10000 233644 ns 233640 ns 3049
BM_Vector_Insert/100 174 ns 174 ns 4001143
BM_Vector_Insert/1000 554 ns 554 ns 1276836
BM_Vector_Insert/10000 6928 ns 6928 ns 99816
BM_ArenaVector_Insert/100 58.2 ns 58.2 ns 12159956
BM_ArenaVector_Insert/1000 358 ns 358 ns 1967342
BM_ArenaVector_Insert/10000 4997 ns 4997 ns 138192As we can see from the benchmarks, the arena allocator is 1.6x faster than the standard allocator, and in some cases its 46x faster. These benchmarks were run on an Apple M4. There is a caveat to the benchmarks above. The memory for the arena is allocated outside of the measured part of the code, of course this is not the case when using the standard allocator. Therefore, this is not an apples-to-apples comparison, but more similar to a real world scenario.
Limitations
One of the biggest limitations is that arena allocators do not support individual deallocations. This means that all the allocations must have similar lifetimes, for example a frame buffer. Therefore, an arena is not good for objects with unpredictable lifetimes or long lifetimes since you cannot make the full use of an arena's advantages. For example, I might allocate something right at the end of my arena which I need throughout the lifetime of my program, this means I must keep the entire arena allocated even though anything allocated before it might not be needed at this point.
Although, the allocator does not perform as well when using std::vector compared to std::unordered_set. I did not explore how the resizing of the std::vector actually worked when using my custom allocator and this might be a factor to consider. Nonetheless, when using reserve() we would expect the Arena to be on par with the standard allocator at minimum.
References
For this project I leant upon previous work by Digital Grove's Untangling Lifetimes, who first introduced me to the area formally. When implementing my own arena I leant on Ng Song Guan's Arena Implementation, gingerBills' Memory Allocation Strategies, and Google's Protobuf Arena.